MIT6.824-MapReduce
Introduction - MapReduce
前言:笔者建筑学毕业,计算机知识全靠自学,听说这个比较锻炼能力,因此尝试去做。因为只学习了C++,而网上的所有LAB都是用go实现的,懒得去学go了,直接用C++实现,当然,本人菜狗一只,几乎全程参考了大佬的代码,以下是链接:https://github.com/tjumcw/6.824
除此之外还参考了一些笔记:
1.知乎大佬的2021版gitbook完整笔记:
https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-01-introduction/1.1-fen-bu-shi-xi-tong-de-qu-dong-li-he-tiao-zhan-drivens-and-challenges
2.微信公众号 多颗糖:
https://mp.weixin.qq.com/s?__biz=MzIwODA2NjIxOA==&mid=2247484185&idx=1&sn=055263242bfb70e727b8fffb1d879301&chksm=970980dca07e09ca97fef2fda5ad34d5f56df4edc9ce487bc69291fb621fbdd6db4af6a57560&scene=178&cur_album_id=1751707148520112128#rd
1. Introduction
本课程是2021 MIT 6.824 分布式系统,这里先简单介绍一下我所理解的分布式系统
分布式系统的核心是通过网络来协调的一组计算机,他们共同完成一些任务。我们在课程中将会重点介绍一些案例,例如大型网站的储存系统,大数据运算,比如MapReduce,以及一些更奇妙的技术,比如点对点的文件共享。
在介绍分布式之前,需要提醒大家,在你设计一个系统时,如果可以在一台计算机上面解决问题,那么就不需要用到分布式,因为分布式会让问题的解决变得复杂。
人们使用大量的相互协作的计算机的驱动力是:
- 可以获得更高的计算性能。大量的计算机意味着大量的并行运算,大量CPU,大量内存,以及大量磁盘并行运行
- 构建分布式可以提供容错(tolerate faults)。比如两台计算机运行完全相同的任务,如果其中一台发生故障,可以切换到另外一台
- 一些问题天然在空间上是分布的,例如在杭州的银行A往上海的银行B转账。
- 最后一个原因,人们构建分布式系统来达成一些安全的目标。比如一些代码并不被信任,但是我们又需要与他进行交互,这些代码不会立即表现出恶意或者bug。我们不会想要信任这些代码,因此我们可以将这些代码分布在其他计算机上运行,自己的代码在自己的计算机上运行,通过一些网络协议可以进行通信。所以,当我们担心安全问题时,可以将系统进行分布式设计,这样可以限制出错域
2. 支持分布式系统的底层基础架构
课程不会花大量时间在分布式的应用程序上,而是着重介绍支撑这些分布式应用程序开发的底层基础架构,常见的有:
- storage:存储基础架构,比如键值服务器,文件系统等
- computation:计算框架,用来编排或构建分布式应用程序,比如经典的MapReduce
- communication:分布式系统逃不开的网络通信问题,比如后续会讨论到的RPC
需要关注的是RPC提供的语义(同时也是分布式系统和通信关联的部分):
- utmost once :最多一次
- exactly once :恰好一次
- at least once:至少一次
对于分布式系统的底层基础架构,我们通常抽象的目标是做到让使用者觉得和单机操作无异,这个是非常难实现的(也就是隐藏分布式中各类难题的具体实现,对外暴露时争取和普通本地串行函数别无二致)
3. 分布式系统的3个重要特性
fault tolerance:容错性
- availability:可用性,一般用p999等指标衡量
- 主要依赖replication复制技术
- recoverability:可恢复性,当机器崩溃或故障时,在重启时恢复正常工作状态
- 主要依赖logging or transaction日志或事务一类的技术
- durable storage,需要将数据写入持久化的存储器,便于后续恢复工作
- availability:可用性,一般用p999等指标衡量
consistency:一致性,即多个服务应该提供一致的服务,客户端请求哪个服务端获取的响应需要一致
关于一致性,有很多不同实现方式:
- 强一致性:多个机器执行的行为,就类似串行执行
- 最终一致性:较为宽松,多个行为执行后,只需要保证最后一个行为的结果在多台服务器都得到相同的表现
performance:分布式系统往往希望能比单机系统要具备更高的性能,但是提高性能本身和提供容错性、一致性是冲突的。
性能一般涉及两个指标:
- throughput 吞吐量:目标是吞吐量与部署的机器数成正比
- latency 低延迟:其中一台机器执行慢就会导致整个请求响应慢,这称为尾部延迟(tail latency)
至于什么是尾部延迟,这不进行展开
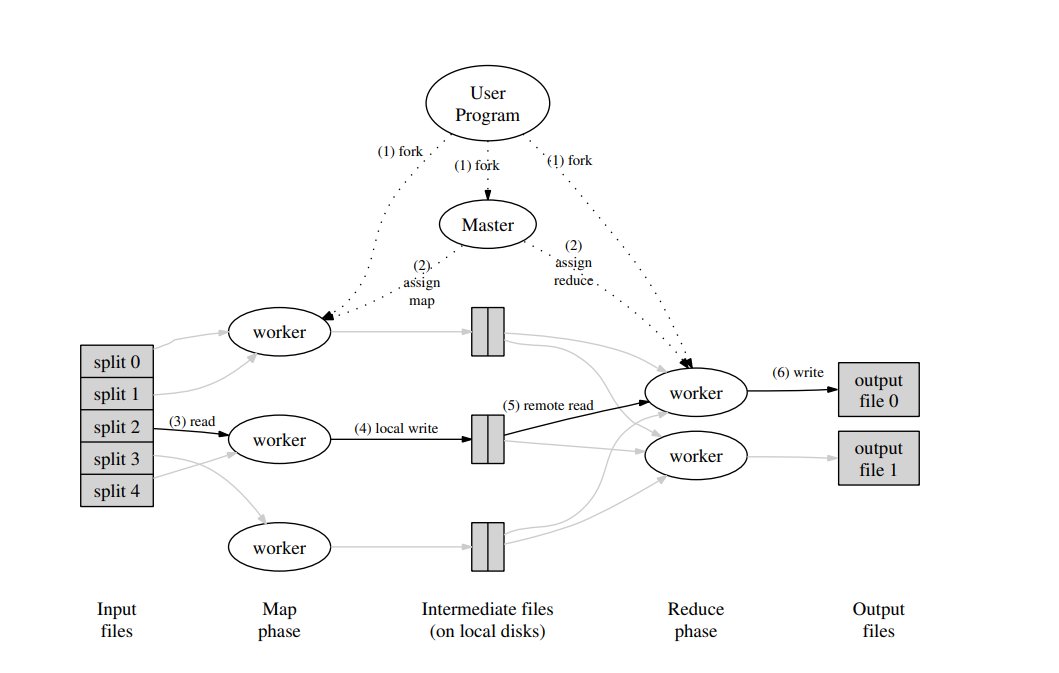
4. Lab1 - MapReduce
前期需要阅读论文,虽然网上有很多解析文章,论文还是自己过一遍比较好
基本框架: