零拷贝技术:Direct I/O
Direct I/O 是一种文件 I/O 操作模式,其核心特点是 绕过操作系统的 Page Cache (页缓存),让数据直接在应用程序的用户空间缓冲区和存储设备(磁盘 / SSD / NVMe) 之间进行传输,这和标准的 Buffered I/O (数据经过 Page Cache) 形成鲜明对比。
Direct I/O
我们先来看一个例子,来直观的认识一下 Direct I/O。我们使用 dd 命令来生成一个 128M 的全零的文件,在不加任何 flag 的情况下,dd 使用的是 Buffered I/O ,所以数据是要经过 Page Cache 的,而且在 dd 完成之后,文件数据仍然会在 Page Cache 中驻留一段时间。这一点我们可以通过命令 vmtouch 来验证。执行 vmtouch -v 命令,该命令会显示出来指定文件在 Page Cache 中的驻留情况,我们刚使用 dd 走 Buffered I/O 生成的文件内容全部都被缓存在 Page Cache 中。
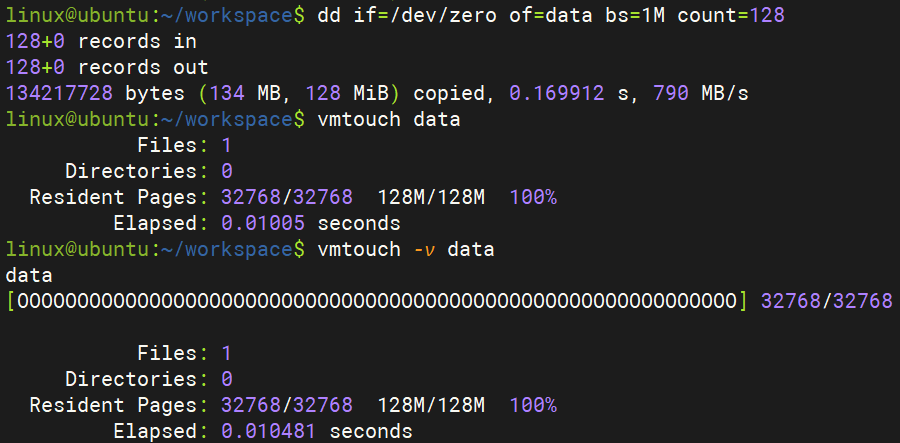
Resident Pages: 3/6 表示 6 个内存页中有 3 个在缓存中(50%),当然上图是100%
下面我们还是使用刚才的 dd 命令,再加上 oflag=direct 参数,该参数表示 dd 输出文件时使用 Direct I/O。这次在文件生成之后,立刻使用 vmtouch 去查看该文件时,发现该文件完全没有在 Page Cache 中驻留,这和 Direct I/O 的行为是一致的。
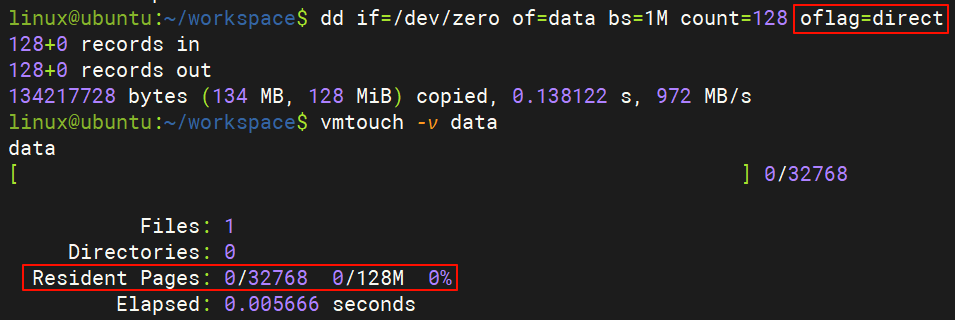
那 dd 加与不加 oflag=direct 的区别是啥呢?我们再次搬出 strace 神器,来跟踪一下这两种情况下 dd 调的系统调用的情况。
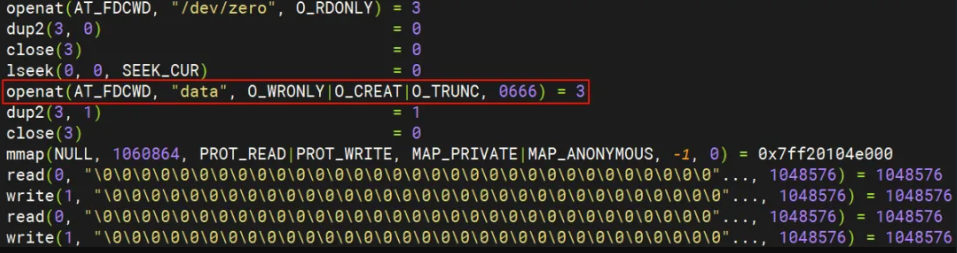
这是dd 不加 oflag=direct 的情况,走 Buffered I/O 的情况。
这是dd 加了 oflag=direct 的情况,走 Direct I/O 的情况。
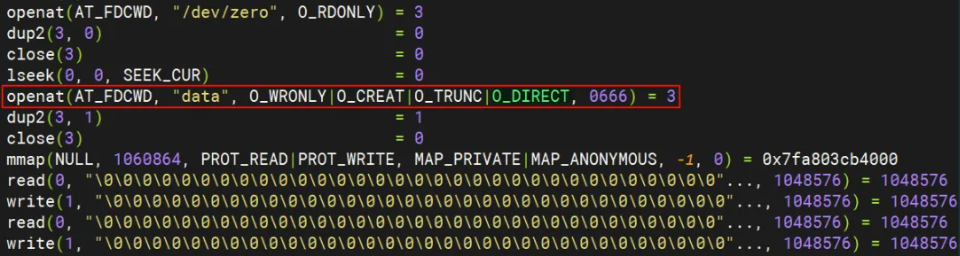
可以发现两种情况的区别在于使用 Direct I/O 时,打开文件的系统调用 openat 多了个 O_DIRECT flag。
所以在 Linux 上,通过在调用 open() 系统调用打开文件时,在 flags 参数中指定 O_DIRECT 标志就可以启用 Direct I/O 了,后面对这个文件的读写就不会经过 Page Cache 了。当程序使用 read 或 write 系统调用对以 Direct I/O 方式打开的文件进行读写的时候,内核会把用户态提供的缓冲区 “钉”(pin)在内核态,防止用户态缓冲区背后的物理页面被换出,因为接下来内核会直接使用这个用户态缓冲区背后的物理页面进行 DMA 传输,和存储介质交换数据。在这个过程中数据的搬运全部由 DMA 完成,CPU 不参与数据的搬运(没有 memcpy)。
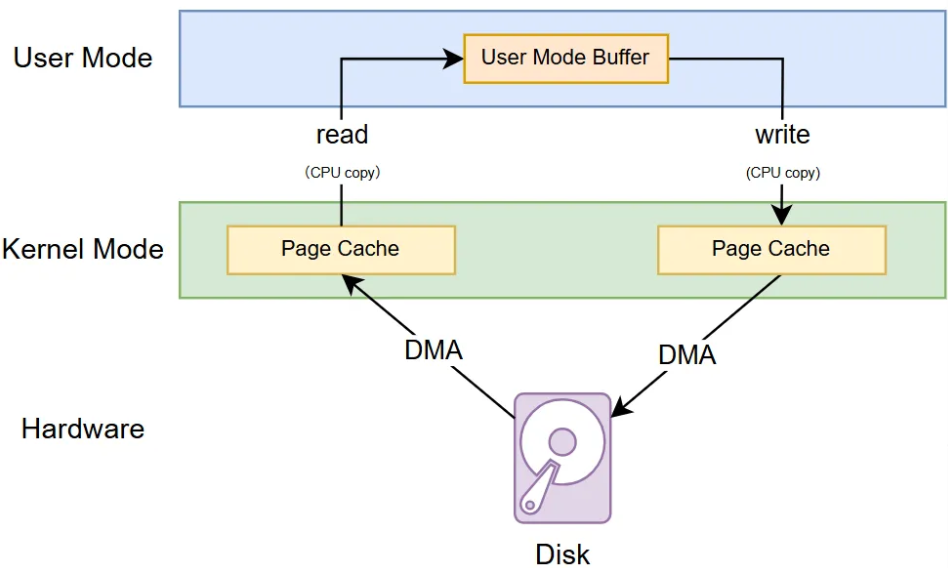
Buffered I/O 的读写示意图如下,程序需要调用 read 系统调用把(输入文件的)内核态的 Page Cache 中的数据通过 CPU 拷贝至用户态缓冲区中,然后调用 write 系统调用把用户态缓冲区中的数据通过 CPU 拷贝至内核态(输出文件的) Page Cache 中。
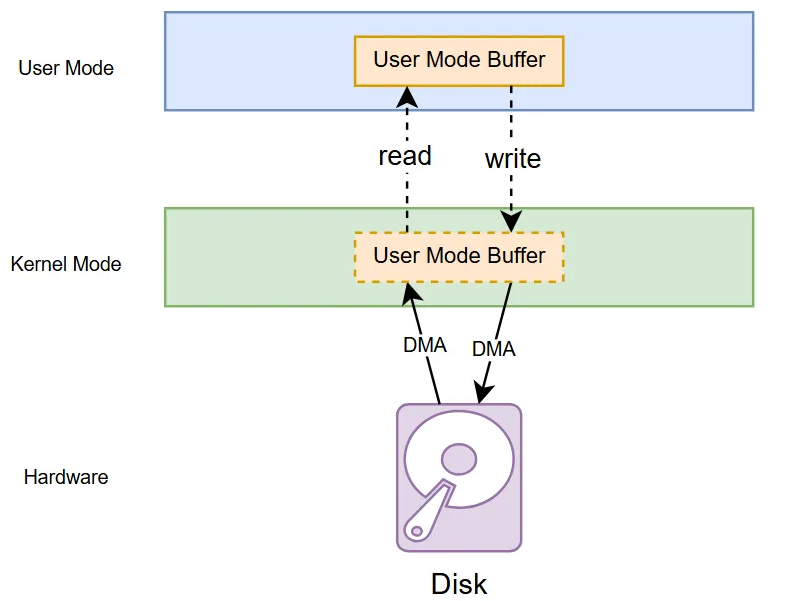
Direct I/O 的读写示意图如下,这里的 read 和 write 系统调用仅仅是起一个控制作用,不会有真正的(CPU)数据拷贝,用户态的缓冲区被 pin 在了内核态,DMA 直接使用用户态的缓冲区进行数据搬运。
优点
消除了内存拷贝:数据在用户态缓冲区和硬件之间通过 DMA 传输,没有 CPU 的内存拷贝。
节省系统内存:不占用 Page Cache,这对于处理超大文件或需要大量内存给应用程序自身使用的场景(如数据库)至关重要,避免了“双缓存”问题(应用自己缓存一份,内核缓存又一份)。
更可预测的 I/O 延迟: 消除了内核 Page Cache(如刷脏页、换入换出)带来的延迟抖动,使得 I/O 时间更真实地反映硬件性能。对于实时性要求高的应用可能有益。
减少脏数据丢失的可能:由于数据不经过 Page Cache,对于写操作来说就不会在 Page Cache 中留下脏页,避免了出现异常情况,比如系统掉电导致的数据丢失。
缺点
用户空间缓冲区地址必须对齐:由于用户态缓冲区直接参与 DMA,为了高效地进行 DMA 操作,用户态缓冲区必须在内存中对齐到存储设备逻辑块大小的倍数(通常是 512 字节或 4KB)。
无预读/合并写: 内核不会为 O_DIRECT 文件执行预读优化,也不会合并小的连续的写入操作,每个 read/write 系统调用通常直接对应一个 I/O 请求。