C/C++关键字汇总
1. extern
1.1 使用
extern是一个关键字,可以用来修饰函数和变量,当extern修饰一个变量或函数时时,就是在声明这个变量(函数),告诉编译器在外部文件中已经有这个变量(函数),直接通过编译就行了,别给我报错。
一般我们的项目会有很多的.cpp文件,当我们需要在一个文件中使用另外一个文件中的变量时,就需要用到extern
具体用法示意如下:
1
2
3
4
// file1.cpp
#include <iostream>
int globalVar = 0; // 全局变量
1
2
3
4
5
// file2.cpp
#include <iostream>
extern int globalVar;
void func() {globalVar = 10;} // 直接使用这个全局变量
但凡是使用到这个全局变量的文件,使用extern即可,函数也是一样的道理。
1.2 注意事项
在使用extern时我们可能会写出这样的代码 :
1
2
3
4
// file1.cpp
#include <iostream>
int globalVar = 0;
1
2
3
4
5
// file2.cpp
#include <iostream>
extern int globalVar = 100;
void func() {globalVar = 10;}
代码的意思是我们使用extern引入外部变量的时候,一并进行了赋值,此时编译器会报错,这个错误是在链接的时候发生的错误,为“找到一个或多个多重定义的符号”
原因是赋值后,即便是加上extern关键字,系统也会分配内存,也就是定义,而非声明,此处存在重复定义
1.3 补充
当我们有多个文件需要大量引用外部变量或函数的时候,通常将所有的全局变量和常用全局函数都写在一个.cpp文件中,然后用同名的.h文件放这些变量与函数的声明(即头文件),这样其他文件需要使用外部变量和函数时,就只需要包含其中的头文件即可,显得高效又简洁。如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//文件1cpp代码
#include "2.h"
int main()
{
show();
printf("%d", globalVar);
}
//文件2.cpp代码,用于定义与实现
#include "2.h"
int globalVar = 10;
void show()
{
printf("hello world");
}
//文件2.h代码,用于声明
#pragma once //防止重复包含
#include <iostream>
extern int globalVar;
void show();
这样的好处是,我们在文件1中使用这些全局变量的时候,就不需要使用extern来进行声明了~
2. volatile
参考链接:https://www.midlane.top/wiki/pages/viewpage.action?pageId=26183175
volatile是易变的、不稳定的意思,通过volatile关键字可以定义易变变量。volatile在嵌入式开发中具有举足轻重的作用,因为嵌入式开发人员要经常同中断、底层硬件等打交道,这些都要用到volatile,因此嵌入式开的程序员必须掌握volatile的使用。
要理解volatile的作用,我们需要先分析一下现代计算机的分级存储系统。现代计算机中,存储系统一般分为以下几级:
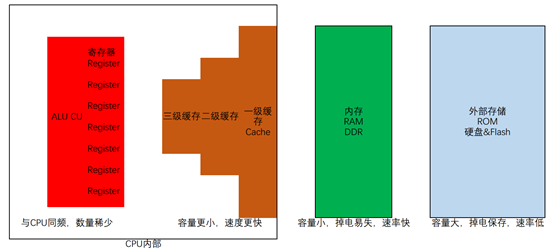
上述各部分中,与volatile有关的是寄存器部分。一般情况下,我们都认为数据是保存在内存中的,比如我们定义的各种变量就是保存在内存里面。但是,当一个数据需要频繁使用时,从内存把数据载入CPU或是从CPU将数据写回内存将消耗大量的时间。因此,可以把数据保存在寄存器里,因为寄存器的存取速度与CPU的计算速度相同,CPU计算的有多快,寄存器就可以以多快的速度进行存取。
编译器根据以上特点,在编译程序时,会对具有上述特点的一些变量(比如常见的循环控制变量)进行优化,将它们保存在寄存器中。
1
2
3
4
5
int i; // 理论上将i存储中寄存器中可以加快速度
for(i = 0; i < 100000000; i++)
{
// do something
}
但是,一味地为了速度去优化变量的存储位置是有问题的,如果这个变量被多个代码段所共享(比如全局变量),那么,将它保存在寄存器中,对它所做的改变将不能及时写入内存,同时,CPU也不能及时从内存得知该数据是否已经被改变。如果这个变量是一个关键的状态检测变量(比如CPU的中断变量),那么,它的状态改变就有可能在第一时间未被检测到。
所以,为了防止编译器自作主张地去改变变量的存储位置,可以用volatile修饰变量。准确说就是,每次要用到这个变量时,都必须从内存中直接读取这个变量的值,而不是使用在它在寄存器中的备份。
1
2
3
4
5
volatile int i; // 每次用于i时都要从内存去取值
for(i = 0; i < 100000000; i++)
{
// do something
}
优化的内容还不止这一个,编译器还会自动分析程序,将一些看似没有意义的语句进行优化(比如,连续对同一个变量多次赋值,编译器可会只取最后一次赋值,中间的赋值被省略)。同理,使用volatile修饰之后,类似的优化将被取消。
1
2
3
4
5
volatile int i;
i = 1; // 这些代码不会被优化
i = 2; // 这些代码不会被优化
i = 3; // 这些代码不会被优化
i = 4;
总结一下volatile关键字的作用:
中断服务程序中修改的供其他程序检测的变量需要加volatile。
多任务环境下各任务间共享的变量应该加volatile。
存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能有不同的意义,以下是一种常见的写法:
#define GPIOCOUT *((volatile unsigned*)0xb000a000)这行代码的实际含义是将内存地址0xb000a000强制转换为指向无符号整数的指针,并使用解引用操作符*访问该地址上的值。
3. register
register关键字与volatile关键字作用刚好相反。使用register修饰后,编译器会尽可能将这个变量存储在CPU内存的寄存器中,而不是通过内存寻址去访问。
注意,CPU的寄存器是数量有限的,一般也就那么几个或是几十个,如果用户定义了很多的register变量,那么并不是所有的register变量都会真的存储在寄存器中。
1
2
3
4
5
register int i;
for(i = 0; i < 100000000; i++)
{
// do something
}
注意:
使用register修饰的变量必须是CPU寄存器所能接受的类型,这意味着register变量必须是一个值,且长度小于或等于整型数据的长度。因为register变量可能不存放在内存中,所以不能对register变量使用“&”进行取地址操作。
4. explicit
在C++中,explicit关键字用于防止类构造函数、转换运算符或其他函数的隐式自动转换。使用explicit可以提高代码的可读性和健壮性,避免意外的类型转换导致的错误。
4.1 防止构造函数隐式转换
在C++中,单参数的构造函数默认可以作为转换构造函数,用于隐式转换类型。使用explicit关键字可以防止这种隐式转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Widget {
public:
explicit Widget(int size) {
// 构造函数实现
}
};
void doSomething(Widget w) {
// 函数实现
}
// 示例使用
Widget w(10); // 直接初始化是允许的
// doSomething(10); // 错误:不能隐式转换int到Widget
doSomething(Widget(10)); // 正确:显式转换
4.2 防止转换运算符的隐式转换
C++中的类可以定义转换运算符,用于将一个对象隐式转换为另一种类型。使用explicit关键字可以防止转换运算符的隐式转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
class Boolean {
bool value;
public:
Boolean(bool value) : value(value) {}
explicit operator bool() const {
return value;
}
};
// 示例使用
Boolean b(true);
bool val = b; // 错误:不能隐式转换Boolean到bool
bool val2 = static_cast<bool>(b); // 正确:显式转换
在这个例子中,Boolean类的转换运算符被标记为explicit,阻止了其隐式转换到bool。
注意一下该例子中
operator bool()的用法,可以将类对象用作bool值,例如Boolean obj(true); if(obj) {;}
5. noexcept
在讲noexcept之前,先说一下C98中的异常规范。
5.1 C++98 中的异常规范
throw 关键字除了可以用在函数体中抛出异常,还可以用在函数头和函数体之间,指明当前函数能够抛出的异常类型,这称为异常规范,有些教程也称为异常指示符或异常列表。请看下面的例子:
1
double func1 (char param) throw(int);
函数 func1 只能抛出 int 类型的异常。如果抛出其他类型的异常,try 将无法捕获,并直接调用 std::unexpected。
如果函数会抛出多种类型的异常,那么可以用逗号隔开,
1
double func2 (char param) throw(int, char, exception);
如果函数不会抛出任何异常,那么只需写一个空括号即可,
1
double func3 (char param) throw();
同样的,如果函数 func3 还是抛出异常了,try 也会检测不到,并且也会直接调用 std::unexpected。
1. 虚函数中的异常规范
C++ 规定,派生类虚函数的异常规范必须与基类虚函数的异常规范一样严格,或者更严格。只有这样,当通过基类指针(或者引用)调用派生类虚函数时,才能保证不违背基类成员函数的异常规范。请看下面的例子:
1
2
3
4
5
6
7
8
9
10
11
12
class Base {
public:
virtual int fun1(int) throw();
virtual int fun2(int) throw(int);
virtual string fun3() throw(int, string);
};
class Derived: public Base {
public:
int fun1(int) throw(int); //错!异常规范不如 throw() 严格
int fun2(int) throw(int); //对!有相同的异常规范
string fun3() throw(string); //对!异常规范比 throw(int, string) 更严格
}
2. 函数声明定义与异常
C++ 规定,异常规范在函数声明和函数定义中必须同时指明,并且要严格保持一致,不能更加严格或者更加宽松。请看下面的几组函数:
1
2
3
4
5
6
7
8
9
10
11
// 错!定义中有异常规范,声明中没有
void func1();
void func1() throw(int) { }
// 错!定义和声明中的异常规范不一致
void func2() throw(int);
void func2() throw(int, bool) { }
// 对!定义和声明中的异常规范严格一致
void func3() throw(float, char *);
void func3() throw(float, char *) { }
3. C++11弃用缘故
异常规范的初衷是好的,它希望让程序员看到函数的定义或声明后,立马就知道该函数会抛出什么类型的异常,这样程序员就可以使用 try-catch 来捕获了。如果没有异常规范,程序员必须阅读函数源码才能知道函数会抛出什么异常。
不过这有时候也不容易做到。例如,func_outer() 函数可能不会引发异常,但它调用了另外一个函数 func_inner(),这个函数可能会引发异常。再如,编写的一个函数调用了老式的一个库函数,此时不会引发异常,但是老式库更新以后这个函数却引发了异常。
其实,不仅仅如此,
异常规范的检查是在运行期而不是编译期,因此程序员不能保证所有异常都得到了 catch 处理。
由于第一点的存在,编译器需要生成额外的代码,在一定程度上妨碍了优化。
模板函数中无法使用。比如下面的代码,
1 2 3 4 5
template<class T> void func(T k) { T x(k); x.do_something(); }
赋值函数、拷贝构造函数和 do_something() 都有可能抛出异常,这取决于类型 T 的实现,所以无法给函数 func 指定异常类型。
实际使用中,我们只需要两种异常说明:抛异常和不抛异常,也就是 throw(…) 和 throw()。
所以 C++11 摒弃了 throw 异常规范,而引入了新的异常说明符 noexcept。
5.2 C++11 noexcept
noexcept 紧跟在函数的参数列表后面,它只用来表明两种状态:”不抛异常” 和 “抛异常”。
1
2
3
4
5
void func_not_throw() noexcept; // 保证不抛出异常
void func_not_throw() noexcept(true); // 和上式一个意思
void func_throw() noexcept(false); // 可能会抛出异常
void func_throw(); // 和上式一个意思,若不显示说明,默认是会抛出异常(除了析构函数,详见下面)
对于一个函数而言,
- noexcept 说明符要么出现在该函数的所有声明语句和定义语句,要么一次也不出现。
- 函数指针及该指针所指的函数必须具有一致的异常说明。
- 在 typedef 或类型别名中则不能出现 noexcept。
- 在成员函数中,noexcept 说明符需要跟在 const 及引用限定符之后,而在 final、override 或虚函数的 =0 之前。
- 如果一个虚函数承诺了它不会抛出异常,则后续派生的虚函数也必须做出同样的承诺;与之相反,如果基类的虚函数允许抛出异常,则派生类的虚函数既可以抛出异常,也可以不允许抛出异常。
需要注意的是,编译器不会检查带有 noexcept 说明符的函数是否有 throw。
1
2
3
void func_not_throw() noexcept {
throw 1; // 编译通过,不会报错(可能会有警告)
}
这会发生什么呢?程序会直接调用 std::terminate,并且不会栈展开(Stack Unwinding)(也可能会调用或部分调用,取决于编译器的实现)。另外,即使你有使用 try-catch,也无法捕获这个异常。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
using namespace std;
void func_not_throw() noexcept {
throw 1;
}
int main() {
try {
func_not_throw(); // 直接 terminate,不会被 catch
} catch (int) {
cout << "catch int" << endl;
}
return 0;
}
所以程序员在 noexcept 的使用上要格外小心!
这里额外说一下std::terminate :
std::terminate是 C++ 标准库中的一个函数,用于终止程序的执行。具体来说,std::terminate函数会导致程序立即终止,并调用处理程序(terminate handler),默认情况下,这会导致调用std::abort()函数来终止程序。在什么情况下会调用
std::terminate呢?
未捕获的异常: 当一个异常没有被任何
try-catch块捕获时,C++ 标准库会调用std::terminate来终止程序的执行。这种情况下,程序无法继续正常执行,因为没有适当的异常处理机制。调用
std::terminate()函数: 如果在程序中显式调用了std::terminate()函数,那么程序会立即终止。通常情况下,这种调用是为了处理程序无法继续正常执行的情况。异常规范: 当函数有异常规范(exception specification)时,并且发生了不符合规范的异常抛出,也会导致调用
std::terminate。在大多数情况下,程序员不会直接调用
std::terminate,而是依赖于异常处理机制来处理程序中的异常情况。然而,了解std::terminate的存在和工作原理对于理解 C++ 异常处理的整体机制非常重要。
noexcept 除了可以用作说明符(Specifier),也可以用作运算符(Operator)。noexcept 运算符是一个一元运算符,它的返回值是一个 bool 类型的右值常量表达式,用于表示给定的表达式是否会抛出异常。例如,
1
2
3
4
5
6
void f() noexcept {
}
void g() noexcept(noexcept(f)) { // g() 是否是 noexcept 取决于 f()
f();
}
其中 noexcept(f) 返回 true,则上式就相当于 void g() noexcept(true)。
析构函数默认都是 noexcept 的。C++ 11 标准规定,类的析构函数都是 noexcept 的,除非显示指定为 noexcept(false)。
1
2
3
4
5
6
7
8
9
10
11
class A {
public:
A() {}
~A() {} // 默认不抛出异常
};
class B {
public:
B() {}
~B() noexcept(false) {} // 可能会抛出异常
};
在为某个异常进行栈展开的时候,会依次调用当前作用域下每个局部对象的析构函数,如果这个时候析构函数又抛出自己的未经处理的另一个异常,将会导致 std::terminate。所以析构函数应该从不抛出异常。
5.3 显式指定异常说明符的好处
显示指定 noexcept 的函数,编译器会进行优化
因为在调用 noexcept 函数时不需要记录 exception handler,所以编译器可以生成更高效的二进制码(编译器是否优化不一定,但理论上 noexcept 给了编译器更多优化的机会)。另外编译器在编译一个
noexcept(false)的函数时可能会生成很多冗余的代码,这些代码虽然只在出错的时候执行,但还是会对 Instruction Cache(指令缓存) 造成影响,进而影响程序整体的性能。容器操作针对
std::move的优化举个例子,一个
std::vector<T>,若要进行reserve操作,一个可能的情况是,需要重新分配内存,并把之前原有的数据拷贝(copy)过去,但如果 T 的移动构造函数是 noexcept 的,则可以移动(move)过去,大大地提高了效率。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
#include <iostream> #include <vector> using namespace std; class A { public: A(int value) { } A(const A &other) { std::cout << "copy constructor"; } A(A &&other) noexcept { std::cout << "move constructor"; } }; int main() { std::vector<A> a; a.emplace_back(1); a.emplace_back(2); return 0; }
上述代码可能输出:
1
move constructor
但如果把移动构造函数的 noexcept 说明符去掉,则会输出:
1
copy constructor
你可能会问,为什么在移动构造函数是 noexcept 时才能使用?这是因为它执行的是 Strong Exception Guarantee,发生异常时需要还原,也就是说,你调用它之前是什么样,抛出异常后,你就得恢复成啥样。但对于移动构造函数发生异常,是很难恢复回去的,如果在恢复移动(move)的时候发生异常了呢?但复制构造函数就不同了,它发生异常直接调用它的析构函数就行了。